Le langage SQL
Aperçu des sections
-
Ce cours permet de découvrir le langage SQL et d'approfondir des notions de bases.
-
Bon, jusqu'ici, vous avez découvert un logiciel de gestion de base de données, et vous l'avez utilisé pour commencer à concevoir votre BDD. Mais qu'en est-il du SQL ? On va faire un premier détour sur ce langage absolument incontournable lorsque l'on travail sur une base de données.
Pour ce faire, allez dans la partie Export de votre base de données agenceimmo, et faites un export simple. Votre navigateur va télécharger un fichier agenceimmo.sql, ouvrez-le.
Exemples de requêtes SQL que vous devriez trouver à l'intérieur :
Création de la table annonce en utilisant le SQL :
CREATE TABLE `annonces` (
`id` int(11) NOT NULL,
`type` char(1) NOT NULL DEFAULT 'A',
`surface` smallint(5) UNSIGNED NOT NULL DEFAULT 0,
`prix` mediumint(8) UNSIGNED NOT NULL DEFAULT 0,
`description` text NOT NULL,
`ville_id` int(11) NOT NULL,
`active` tinyint(1) NOT NULL DEFAULT 0,
`date_creation` datetime NOT NULL DEFAULT current_timestamp(),
`date_modification` datetime NOT NULL DEFAULT current_timestamp()
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Insertion des données dans la table annonces :
INSERT INTO `annonces` (`id`, `type`, `surface`, `prix`, `description`, `ville_id`, `active`, `date_creation`, `date_modification`) VALUES
(1, 'M', 95, 175000, 'Super annonce de maison a voir très rapidement. Blabla', 1, 1, '2020-01-02 15:45:44', '2020-01-02 15:45:44'),
(2, 'A', 50, 125000, 'super appart', 1, 1, '2020-01-02 17:36:40', '2020-01-02 17:36:40');Création de la table villes :
CREATE TABLE `villes` (
`id` int(11) NOT NULL,
`nom` varchar(255) NOT NULL,
`description` text NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Ajout d'une ville :
INSERT INTO `villes` (`id`, `nom`, `description`) VALUES (1, 'Toulouse', 'La ville rose, une ville bien agréable !');
Ajout des clés :
ALTER TABLE `annonces` ADD PRIMARY KEY (`id`), ADD KEY `ville_id` (`ville_id`);
ALTER TABLE `villes` ADD PRIMARY KEY (`id`);
Ajout de la contrainte ville_id -> ville :
ALTER TABLE `annonces` ADD CONSTRAINT `annonces_ibfk_1` FOREIGN KEY (`ville_id`) REFERENCES `villes` (`id`);
Quand vous travaillez avec un logiciel en GUI, toutes ces requêtes sont générées automatiquement lorsque vous vous servez de l'interface du logiciel. Mais c'est bien PHP qui envoi toutes ces "chaînes de caractères" à MySQL. Et le SGBDR va les interpréter et va les exécuter dans le but de modifier la base de données, que ce soit la structure de la base, ou bien les données.
En revanche, la majorité des requêtes SQL que vous exécuterez dans une application normale viendront du code lui même (contrairement à phpMyAdmin), et ce sera donc à vous d'écrire vos requêtes, à l'intérieur de votre code, dans le but de les envoyer au SGBDR.L'étendu des différentes possibilité des requêtes SQL est très grande, je vous encourage donc à utiliser Internet et ce genre de site (https://sql.sh/) comme aide mémoire. -
Maintenant que l'on a vu le fonctionnement basique d'une base de données, on va aller voir comment se fabrique les requêtes SQL que vous allez majoritairement utiliser dans votre application.
Quand on travaille sur des problématiques de BDD, il y a quatre choses que l'on fait extrêmement régulièrement :
- ajouter des données (ex : ajouter un appartement à mon site d'agence immobilière)
- lire des données (ex : récupérer tous les appartements à vendre sur Toulouse)
- modifier des données (ex : baisser le prix d'un appartement qui ne se vend pas)
- supprimer des données : (ex : retirer un appartement qui a été vendu)
Ces 4 actions, c'est ce qu'on appel en informatique le CRUD :
- Create
- Read
- Update
- Delete
Avec ces quatre actions, vous pouvez faire couvrir 99% des besoins des interactions entre votre code et vos données. Et on peut faire une correspondance avec les opérateurs que propose SQL :
- pour lire des données, l'opérateur est SELECT
- pour ajouter des données, l'opérateur est INSERT INTO
- pour modifier des données, l'opérateur est UPDATE
- pour supprimer des données, l'opérateur est DELETE
-
Lorsque l'on souhaite ajouter des données dans une table, on utilisera l'opérateur INSERT INTO. Il vous faut respecter une certaine syntaxe, qui ressemble à ceci :
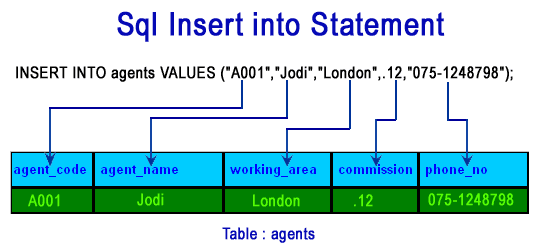
Dans cet exemple, la requête INSERT INTO va demander à la BDD de rajouter une nouvelle ligne dans la table agents, avec les valeurs suivantes :
- agent_code : A001
- agent_name : Jodi
- working_area : London
- commission : 0.12
- phone_no : 075-1248798
Le SGBDR va vérifier la validité de l'action, en prenant en compte le typage des champs, et les différentes contraintes existantes. Si tout est ok, il enregistrera un nouvel agent que vous pourrez retrouver plus tard selon les besoins. De la même manière que si vous l'aviez rajouté manuellement dans phpMyAdmin.
Il y a d'autres syntaxes possibles, voir les détails sur https://sql.sh/cours/insert-into -
La lecture des données de votre BDD représente la plus grosse partie des requêtes que vous écrirez. Normal, on a des données, le but ça reste quand même d'y accéder.
L'opérateur principal pour lire des données, c'est SELECT. Il est couplé avec l'opérateur FROM.
- SELECT : définit les champs que l'on souhaite "récupérer" (lire). On parle bien des colonnes d'une table.
- FROM : définit quelle table l'on souhaite lire. On peut lire plusieurs tables à la fois, mais nous commencerons par une seule.
Dans notre exemple d'agence immobilière, je pourrai écrire ceci par exemple pour récupérer toutes mes villes :
SELECT nom FROM villes;
Cette requête veux dire : "récupère le nom de toutes les villes de ma table villes".
Autrement dit : "récupère-moi le nom de toutes les villes disponibles".
Ce qui aura pour résultat :
La clause WHERE
Si l'on souhaite cibler des éléments selon un critère particulier, on utilisera l'opérateur WHERE.
Par exemple :
SELECT * FROM annonces WHERE id = 3;
Cette requête veux dire : "Récupère-moi tous les champs de l'annonce qui a pour id 3".
Ce qui aura pour résultat :
 Note : le caractère * est ce que l'on appelle un caractère joker. En SQL, il permet de sélectionner tous les champs d'une table.
Note : le caractère * est ce que l'on appelle un caractère joker. En SQL, il permet de sélectionner tous les champs d'une table.Autres opérateurs liés à la clause WHERE :
Les clauses AND/OR
Si vous souhaitez sélectionner des éléments selon des critères plus précis (par exemple : le prix), vous allez pouvoir améliorer votre requête en utilisant des opérateurs logique (comme en programmation). Le SGBDR se chargera de vérifier votre condition, et de vous retourner un jeu de résultat correspondant à votre recherche.
Exemple : recherche d'annonces dont le prix est compris entre 120000€ et 150000€ :
SELECT * FROM annonces WHERE prix >= 120000 AND prix <= 150000
Cette requête veux dire : "Sélectionne-moi tous les appartements qui ont un prix compris entre 120000€ et 150000€".
Résultat :

L'opérateur OR fonctionne de la même manière :
SELECT * FROM annonces WHERE ville_id = 1 OR ville_id = 2;
Cette requête renverra tous les biens dont le champ ville_id est égal à 1 ou à 2 :

La clause ORDER BY
Si vous souhaitez obtenir un résultat trié, vous pouvez utiliser l'opérateur ORDER BY
SELECT * FROM annonces
WHERE ville_id = 1
AND active = 1
ORDER BY surfaceCette requête va récupérer tous les biens actifs de la ville 1, et renvoyer le résultat trié par surface :
 Note : c'est typiquement le genre de choses que l'on va déléguer à notre base de données. On aurait très bien pu trier nos résultats dans le code de notre application, mais on préférera s'appuyer sur la BDD pour ce genre d'opérations "simples".
Note : c'est typiquement le genre de choses que l'on va déléguer à notre base de données. On aurait très bien pu trier nos résultats dans le code de notre application, mais on préférera s'appuyer sur la BDD pour ce genre d'opérations "simples".La clause DISTINCT
Cet opérateur vous permet de récupérer toutes les occurrences d'une valeur dans les données d'un champ. Dans notre exemple, si je veux savoir quels sont les types de biens immobiliers que ma BDD contient, je peux faire ceci :
SELECT DISTINCT type FROM annonces;
Note : ancien exemple, sans la clé étrangère type_id.Cette requête va me renvoyer les différentes valeurs existantes dans toutes lignes sur le champ "type" :

On a bien des maisons et des appartements (A et M). Si un jour je rajoute des Lofts (L), cette requête renverrai A/M/L. Cela peux s’avérer utile par exemple lorsque l'on veut construire dynamiquement un formulaire de recherche. Dans notre application, on aura une requête qui ira chercher les différents types de bien (appart, maison, loft), et qui construira un formulaire HTML selon les résultats retournés par la requête SQL afin de donner le choix à l'utilisateur de filtrer ses recherches par types de biens.
Important : on est bien d'accord, il faudra plutôt privilégier la création d'une table type et la relier a annonces à l'aide d'une clé étrangère. Ceci n'est qu'un exemple. => On peut faire un autre exemple avec la colonne prix.Divers
Autres opérateurs très utilisés :
LIMIT : https://sql.sh/cours/limit
-
Pour modifier des données, c'est assez simple, il suffit d'utiliser l'opérateur UPDATE.
Voici un exemple qui me permet de mettre à jour le champ "description" de l'annonce n°2 :
UPDATE `annonces` SET `description` = 'Un petit appartement en ville, parfait pour un primo-accédant.' WHERE `annonces`.`id` = 2;
Remarques :
- UPDATE s'utilises avec le mot clé SET (un peu comme INSERT INTO / VALUES)
- il ne faut pas oublier de cibler la ligne que l'on souhaite modifier (WHERE id = 2)
- tous les backticks dans mon exemple sont optionnels, mais cela reste une bonne pratique pour sécuriser les requêtes SQL et éviter des failles de sécurité. En revanche ils sont obligatoires lorsque l'on manipule des valeurs de types chaînes de caractère (ce qui est le cas dans l'exemple ci-dessus : différence entre la valeur de "description" et de "id")
- dans la clause WHERE de mon exemple, on aurait pu écrire tout simplement WHERE id = 2. Ici, c'est une requête générée par phpMyAdmin, il rajoute un déterminant pour viser le champ "id" de la table "annonces" afin qu'il n'y est pas d’ambiguïté. On en reparle plus tard.
Voici quelques exemples d'utilisation de l'opérateur UPDATE : https://sql.sh/cours/update
REPLACE INTO
L'opérateur REPLACE INTO est une sorte d'opérateur magique. Il va fonctionner de deux manières, selon deux cas de figures :
- soit la ligne visée n'existe pas, et il va donc rajouter une nouvelle ligne avec les nouvelles données (en mode INSERT INTO)
- soit la ligne visée existe déjà, et il va alors passer en mode UPDATE, et remplacer les données par celles présentes dans la requête
Voici un article dédié au REPLACE INTO. C'est un opérateur qui est beaucoup moins utilisé que les UPDATE ou INSERT, mais quand on a besoin de ce genre de choses ça peux être salvateur.
Attention : cet opérateur passe en réalité par une phase de suppression lorsqu'il met à jour une ligne déjà existante. Ce qui peut engendrer des problèmes de clé étrangère si votre ligne est référencée par une autre table. -
Si vous souhaitez supprimer des données, il vous faudra utiliser l'opérateur DELETE. Il fonctionne de manière assez simple, mais il faut faire attention car les données seront réellement supprimées, et il sera alors assez compliqué de revenir en arrière. Il existe néanmoins différentes techniques pour qu'un DELETE n'efface pas de données importantes :
- prévoir des flags actif/inactif au lieu d'une suppression brute
- avoir des clés externes correctement configurées (il vous sera impossible de supprimer une ville qui recense encore des appartements à vendre par exemple)
- utiliser des systèmes de transaction. Fonctionnalités des SGBDR, mais plus complexes à mettre en œuvre. On en reparlera plus tard.
- faire des backup de toute la base de manière très régulière. On en reparlera plus tard.
Voici un exemple de requête DELETE :
DELETE FROM `annonces` WHERE `annonces`.`id` = 16
Cette requête supprimera la ligne 16 de la table annonces, à condition que les contraintes de la DB le permettent.
On pourrait aussi supprimer des lignes via un autre critère. Si par exemple on veut supprimer toutes les annonces qui datent de plus de "x mois", on fera une clause WHERE sur le champ "derniere_modification" par exemple (en respectant les conventions : updated_at).
Attention !
La requête suivante ;
DELETE FROM annoncesSupprimera toutes les lignes de la table annonces. Il n'y a pas de clause WHERE, donc le SGBDR va considérer que le DELETE s'applique à toutes les lignes. Donc faites bien attention.
Voir les autres possibilité du DELETE ici : https://sql.sh/cours/delete
-
En plus des opérateurs de base en SQL, et des clauses "logiques" (where, and, etc...), le langage SQL propose de nombreuses fonctions utiles. Les fonctions permettent d'appliquer des traitements sur l'informations, qui seront effectué directement par le SGBDR, avant qu'il ne retourne les résultats. Ce sont bien souvent des fonctions mathématiques, mais il y a aussi la possibilité de faire des opérateurs logiques (if, etc...), du traitement sur les textes (substr, etc...),...
Elles peuvent être très utiles pour décharger une partie du code sur la base de données. C'est à dire qu'on va demander au SGBDR d'effectuer des traitements de nos informations en amont, sans que ce soit au code de s'en charger. Donc, ça peux offrir des gros gains de performances dans certains cas, et aussi d'avoir un code plus léger.
La fonction COUNT()
La fonction COUNT() est une des plus utilisées. Elle permet de compter le nombre de résultats retouné par une requête, au lieu d'avoir les résultats eux même. Si par exemple j'ai une table qui contient des employés, et que je veux veux savoir combien d'employés sont inscrits dans cette table, je peux faire ce genre de requête SQL :
SELECT COUNT(*) FROM employes
Si ma table contient 243 employes, alors le retour de cette requête ne sera pas les informations de chaque employés, mais bien le nombre 243. On peux aussi améliorer notr erequête en y ajoutant différentes clauses :
SELECT COUNT(*) FROM employes WHERE department_id = 3
En admettant que le département 3 concerne les commerciaux, cette requête me renverra le nombre de commerciaux inscrits dans la base. Cette fonctions s'utilise souvent avec la clause GROUP By. Cette clause permet de regrouper des résultats selon certains critères :
SELECT department_id, COUNT(id) AS nombre_employes FROM `employes` GROUP BY department_id
Cette requête me renverra le nombre d'employés par départements (GROUP BY department_id). Les résultats seront présentés sous deux colonnes, la première recensera les id de chaque département, la seconde, le calcul du nombre d'eployés par département graĉe au COUNT().
Exemple sur notre BDD agenceimmo :
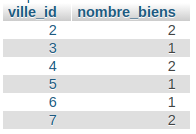
Pour conclure sur la fonction COUNT() : si vous avez une table qui contient 158 672 entrées, préférez vous que votre SGBDR vous renvoi 158 672 résultats, et que vous comptiez les résultats à l'aide de votre langage de programmation préféré ? Ou bien exécuté une fonction COUNT() en SQL, qui ne vous renvoi qu'un seul résultat qui vaut 158 672 ?
Remarque : si vous avez bien regardé les exemples de requêtes, vous avez constaté l'utilisation du mot-clé AS. Ce mot clé permet de renommer un champ dans les résultats de requêtes. Ceci est très pratique si vos noms de champs ne sont pas user-friendly, ou si ils sont générés par un appel de fonction. Dans nos exemples précédents, si je n'avais pas rajouté le AS, le nom de mon champ dans mes résultats serait "COUNT(*)", car ce champ n'existe pas en réalité, et le SGBDR le nomme automatiquement comme ça. Ce n'est pas très propre de garder un champ nommé COUNT(*), donc on le renomme de cette manière : COUNT(*) AS nombre_de_biens.
Les fonctions MIN() et MAX()
Utiles et simples, elles vous permettent de ne récupérer que le minimum ou le maximum de l'ensemble des données d'un champ d'une table. Imaginons dans notre table employés, si nous stockions les salaires des employés à l'intérieur, on pourrai obtenir le salaire minimum et le salaire maximum de cette manière :
SELECT MIN(salaire) FROM employes
SELECT MAX(salaire) FROM employesOn pourrai aussi l'écrire de cette façon, en une seule requête, et en utilisant l'opérateur AS :
SELECT MIN(salaire) as salaire_min, MAX(salaire) as salaire_max FROM employes
Voici un exemple de retour de ce genre de requête sur notre table annonces :

Voici d'autres fonctions d'agrégation que l'on peux utiliser en SQL (AVG, SUM,...) : https://sql.sh/fonctions/agregation. Elles fonctionnent toutes de manière similaire.
=> Il y a pleins d'autres fonctions disponibles en SQL, voir sql.sh.
Comme vous le constaterez, SQL offre de nombreuses fonctions qui existent déjà dans la majorité des langages de programmation. Donc vous serez confronté au dilemme suivant :
- dois-je faire une requête qui me retourne exactement ce dont j'ai besoin ?
- dois-je faire des requêtes "génériques", puis les traiter via quelques lignes de codes par la suite ?
Il n'y a pas de bonnes réponses, mais je pense que la tendance est plutôt sur la deuxième réponse (traitement des données via le code). On aura plutôt tendance à faire des requêtes assez simples, qui renvoient des "blocs" d'informations. Puis ces données seront manipulées via un langage de programmation pour leur appliquer la logique métier. Tout va dépendre de l'équipe, des développeurs, et des choix techniques. Exemple de discussion de comptoir : https://stackoverflow.com/questions/532875/sql-vs-code-where-is-the-balance (EN). Je dirai que la réalité doit se trouver un peu entre les deux approches, au cas par cas.
-
Comme nous l'avons vu, une base de données comporte généralement plusieurs tables. C'est même le cas dans 99.99% des cas. Vous allez donc souvent être emmenés à faire des requêtes qui se basent sur les données de plusieurs tables, et qui vont utiliser les contraintes de clés étrangères existantes dans votre structure de données.
Pour prendre un exemple concret, imaginez que notre site d'agence immobilière propose un champ de recherche qui propose d'afficher toutes les annonces d'une ville. Nous avons déjà une table annonces et un table villes, et les deux sont reliés par une contrainte de clé étrangère "ville_id" présente obligatoirement pour chaque annonces.
Voici un diagramme représentant nos deux tables :
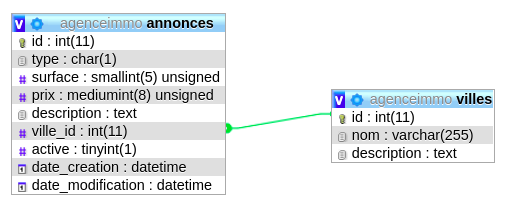
Vous pouvez générer ce digramme dans l'onglet "Plus >> Concepteur" de phpMyAdmin
Revenons à notre formulaire de recherche. Si l'utilisateur saisi "Toulouse", on s'attendrai à avoir une requête SQL de ce type :
SELECT * FROM annonces WHERE active = 1 AND ville = "Toulouse"où bien
SELECT * FROM annonces WHERE active = 1 AND ville_id = "Toulouse"
Sauf que ces requêtes ne marcheront pas, pour deux raisons :
- le champ "ville" n'existe pas dans la table annonce
- le champ "ville_id" de la table "annonces" ne contient pas le nom des villes
Exprimer au SGBDR que l'on souhaite requêter deux tables
Dans un premier temps, pour pouvoir récupérer des données provenant de deux tables, il vous faut les renseigner dans l'opérateur FORM.
Exemple :
SELECT * FROM table_1, table_2
Ensuite, pour exprimer la correspondance qu'il doit y avoir entre deux champs, il faut demander au SGBDR de vérifier que les champs correspondant à la clé étrangère soit égaux
Exemple :
SELECT * FROM table_1, table_2 WHERE table_1.ext_id = table_2.id
Gérer les ambiguïtés
Parfois, deux tables ont des champs qui ont un nom identique (par exemple, les champs description de l'agence immo). Comment le SGBDR peut il savoir si vous souhaitez récupérer le champ description de la table annonces, ou bien de la table ville ? Pour pallier à ceci, il vous suffit de cibler plus précisément vos champs dans votre SELECT.
Exemple :
SELECT annonces.description AS description_annonce, villes.description AS description_ville FROM ......Dans ce cas là, le SGBDR renverra des résultats de requêtes contenant une colonne "description_annonce" et un colonne "description_ville". Si on avait pas fait ça, il renverrai deux champs description, ou bien planterai si l'ambiguité concerne des clauses plus importantes (WHERE, etc...). Ceci est très important à comprendre, car c'est très fréquent d'avoir des champs nommé de manière identiques dans différentes tables (ex : id, dates, noms, description, etc...).
Voici le genre de retour que l'on pourrait attendre de notre SGBDR pour le requête "Toulouse" dans notre formulaire de recherche :

Ici, on a bien toutes les informations essentielles (id, prix, etc...). On a aussi récupéré le nom de la ville, qui pourrait servir à l'affichage, en revanche nous n'avons pas récupéré l'id de la ville ou bien sa description. Ce jeu de résultat ne correspond pas à une table "réelle", c'est une table "virtuelle", qui est générée selon les données qu'on a demandé dans le SELECT.
Et voici la même requête, mais avec la ville "Strasbourg" :

Vous pouvez vérifier les id, cela fonctionne.
-
Les jointures sont utiles lorsque l'on souhaite faire des requêtes sur plusieurs tables, et que l'on se base sur des champs qui ne sont pas forcément reliés par des clés étrangères. De ce fait, il pourrait y avoir des données manquante à la bonne exécution d'une requête, et les jointures permettent de spécifier si telle ou telle données est à prendre en compte dans les résultats d'une requête.
Cette approche peut s'avérer indispensable dans certains cas, mais si la conception de la base est bonne, on ne les utilise pas tant que ça.Voici un récapitulatif des principales jointures existantes :

Comme vous pouvez le voir, on utilise souvent deux ensembles A et B, qui représentent deux tables différentes, pour expliquer les différents résultats possibles des jointures. Ces exemples se basent sur la valeur NULL pour déterminer si on souhaite prendre en compte - ou pas - un enregistrement dans les résultats de la requête, mais on pourrait aussi se baser sur n'importe quel type de valeurs (exemple : WHERE client.budget = 0).
Note : on peut faire des jointures sur autant de tables que l'on souhaite (exemples ici). Il n'y a pas vraiment de limites, si ça n'est la facilité de compréhension de la requête finale. Une requête SQL trop complexe est souvent mauvais signe, et cela va rendre la maintenance de l'application plus compliquée.Un autre élément des jointures, c'est que l'on va parler souvent de la table "de droite" et de la table "de gauche", en référence à l'image plus haut (A et B), et à la place qu'ont les conditions dans votre requête.
- première table déclarée : table "à gauche" de la jointure
- deuxième table déclarée : table "à droite" de la jointure
=> D'où les jointures LEFT et RIGHT.
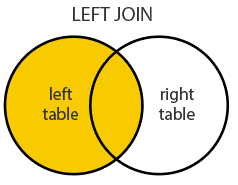
On aura aussi d'autres types d'intersections, tel que INNER (voir image plus haut), mais aussi d'autre moins répandues (outer, self, union, etc...), et qui n'existeront pas forcément dans tous les SGBDR.
Si votre recherche se base sur un champ lié par une clé étrangère, vous n'avez pas besoin des jointures. Un simple WHERE table1.champ1 = table2.champ2 fera l'affaire et sera plus optimisé.Voici quelques liens intéressants sur les jointures :
-
Les sous requêtes (ou requêtes imbriquées) permettent d'exécuter une requête SQL à l'intérieur d'une autre requête SQL. Elles vont vous permettre de vous baser sur les résultats d'une "première requête" (la requête interne) pour déterminer les résultats de la requête principale (requête externe).

On utilisera donc les requêtes imbriquées avec les opérateurs WHERE, IN ou HAVING, afin de trier les résultats de la requête principale sur la base des résultats de la sous-requête.
La sous-requête renvoi un seul résultat
Voici un exemple qui permet d'extraire tous les produits qui ont un prix supérieur au prix moyen des produits :
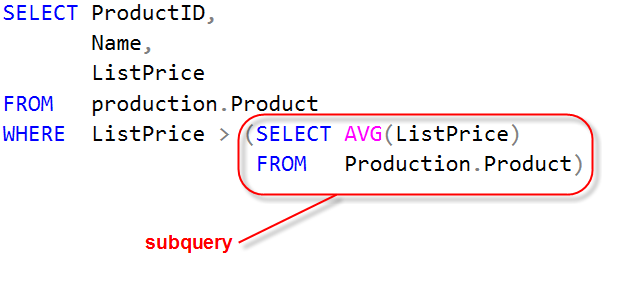
La première requête renverra 23 (prix moyen des produits), puis la requête principale s'exécutera a posteriori avec le paramètre "ListePrice > 23".
Dans cet exemple, la sous-requête nous renvoie "un seul" résultat (23 par exemple), mais on peut aussi travailler avec des sous-requêtes qui renvoient plusieurs résultats.
La sous requête renvoie plusieurs résultats
On utilisera alors plutôt l'opérateur IN pour gérer cela.
Voici un exemple :
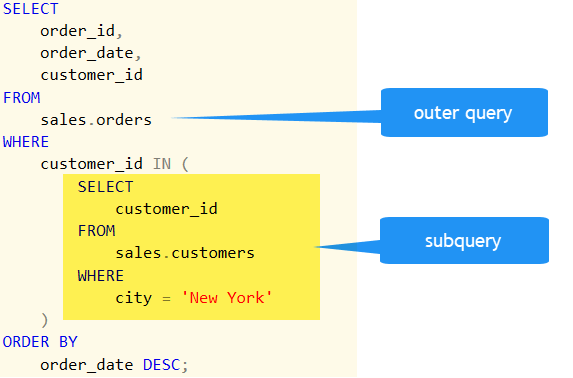
La sous-requête renvoie une liste d'id de clients habitant à New-York. Puis la requête principale se base sur cette liste pour retourner les clients qui ont passé commande. Résultat : on aura toutes les commandes passées par des clients New-Yorkais.
Les requêtes imbriquées ne sont pas très difficile à prendre en main. En revanche, et au même titre que les jointures, on aura tendance à faire 2 requêtes "simples" plutôt qu’une "compliquée". Donc ne vous étonnez pas trop si vous n'en croisez pas beaucoup. On aura ce débat plusieurs fois pour savoir ce qui doit être fait par le code, et ce qui doit être fait par la base de données.Lien intéressant et autres exemples de sous-requêtes :
-
-
Devoir
-
Devoir
-
Devoir
-