Bases de données relationnelles
Aperçu des sections
-
Ce cours permet de découvrir les bases de données relationnelles. Pour ce faire, nous utiliserons l'environnement standard LAMP. Aucune connaissance n'est requise, à part d'être un minimum à l'aise avec l'outil informatique.
Connectez-vous aux cours en ligne en cliquant sur le bouton plus bas. Des replays du cours seront disponibles ici pendant 7 jours.Pour se familiariser avec les bases de données relationnelles, nous utiliserons PHPMyAdmin qui est un des outils adapté pour les débutants et assez facile à utiliser : https://www.phpmyadmin.net. Il faut bien comprendre que PHPMyAdmin ne peut pas fonctionner seul, il s'utilisera dans un environnement de type LAMP que l'on verra dès le début du cours.
Si le besoin s'en ressent, sachez qu'il y a de nombreux tutos sur ce thème sur Internet.C'est parti !
-
Les bases de données sont très importantes lorsque l'on fait du développement web. Elles vont servir à stocker toutes les informations "statiques" dont un logiciel à besoin pour fonctionner. Par exemple, dans ce Moodle, la base de données est assez grande, et va servir à stocker des informations telles que :
- les données sur les élèves (nom, email, mot de passe, etc...). Incontournable pour que chacun puisse se connecter à son propre compte.
- les différentes catégories de cours (HTML, CSS, Javascript, etc...). Afin de structurer l'information.
- les contenus des cours : texte, images, sections, vidéos...
- les différents exercices, et les travaux rendus par les élèves
- et bien d'autres choses encore !
Une base de données sert à figer une informations quelque part, afin de pouvoir la ré-exploiter par la suite. C'est ce que l'on appel la persistance des données. A contrario, les variables que vous utilisez lorsque vous coder un algorithme disparaissent une fois votre programme exécuté. Les bases de données vont donc vous permettre de sauvegarder des informations.

Une base de données n'est rien d'autre qu'un logiciel spécialisé dans le stockage de l'information. À ce titre, il a un mode de fonctionnement bien spécifique. De la même manière qu'un tableur sert à réaliser des feuilles de calcul, ou bien un traitement de texte à faire de la mise en page. D'ailleurs, Microsoft propose dans sa suite bureautique Office un logiciel de base de données (Access), qui est loin d'être une référence dans le secteur, et encore moins quand on parle de développement web.
Les SGBDR
De leur petit nom "Système de Gestion de Base de Données Relationnelles", ces logiciels sont donc spécialisés dans le stockage et l'organisation structurée de l'information. Ils se présentent sous la forme de serveur de données, serveur au sens logiciel du terme (mais pas seulement), comme on parle de serveur web. On va donc pouvoir installer un SGBDR, et lui envoyer des requêtes, de la même manière que l'on envoie des requêtes HTTP à un serveur web. Et au même titre que les serveurs web, il en existe de nombreux :

En revanche, certains SGBDR sont plus populaires que d'autres pour diverses raisons :
- gratuité
- open-source
- présence par défaut chez les hébergeurs
- etc...
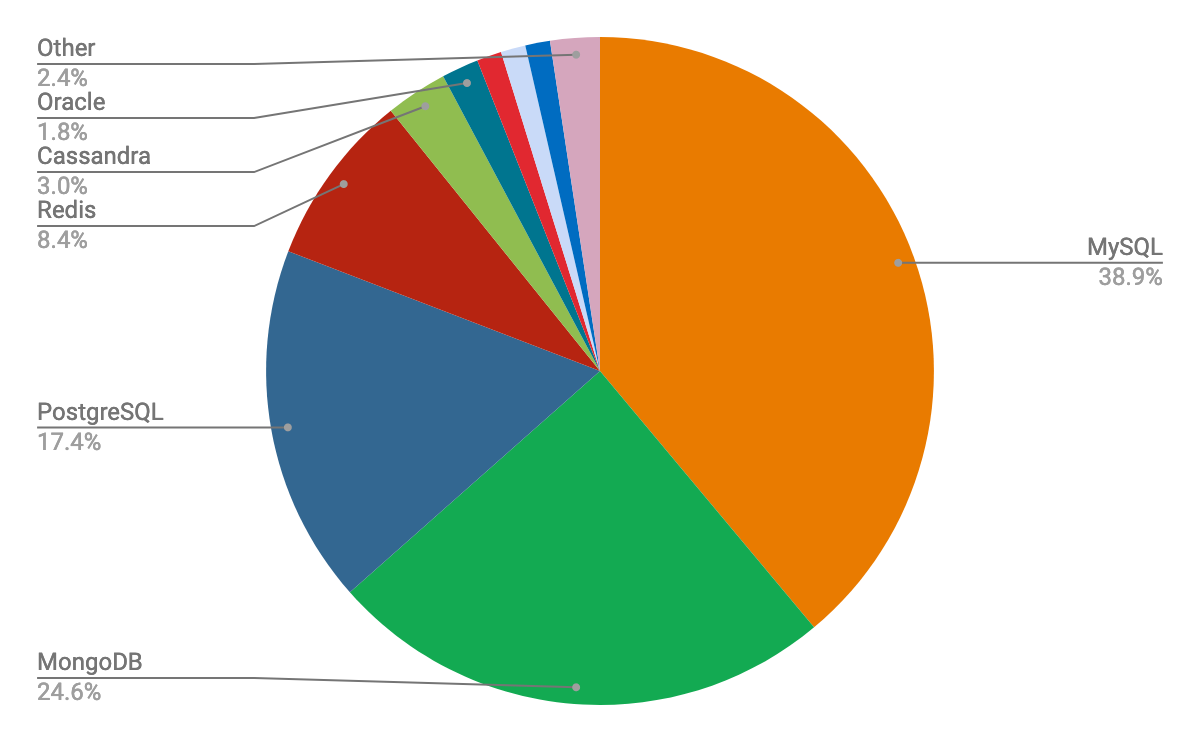
Données de 2019. MySQL est MariaDB sont fusionnés dans ce graphique (je pense)
Lorsque l'on débute en développement web, on a tendance à utiliser MySQL. Il existe un fork très populaire et open-source qui s'appel MariaDB, qui est quasiment la même chose que MySQL. Mais sachez qu'il en existe d'autres qui offrent certaines nuances techniques :
- fonctionnalités plus ou moins avancées
- performances techniques
- existence d'un support professionnel
- etc...
Voici une liste comportant d'autres exemples de SGBD(R) : https://sql.sh/sgbd
Pour conclure cette présentation, retenez que les bases de données sont un aspect critique de la conception d'un logiciel :
- si un problème survient, et que l'accès à vos données est interrompu, votre application est inutilisable.
- si votre code requête mal votre base de données, votre application sera lente.
- si vous avez mal conçu votre DB, vous allez vous tirer les cheveux pour manipuler l'information.
Donc même si les bases de données ne sont pas du code en tant que tel, elles font parties intégrante de votre application (et bien souvent du métier de développeur).
Rôle des développeurs front-end et back-end
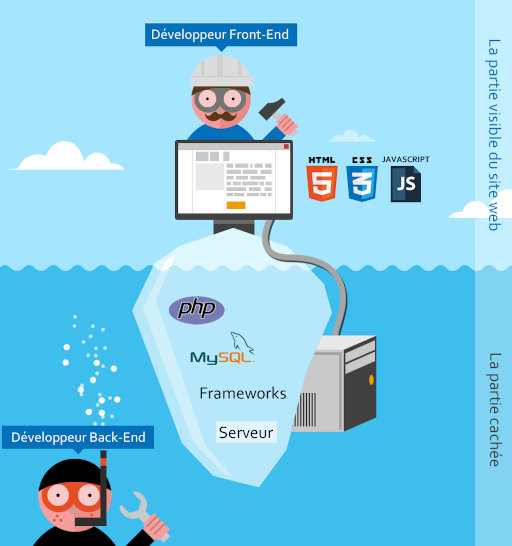
La partie DB est réservée au développeur back-end. Le métier d'administrateur de base de données existe, mais dans de nombreux cas, c'est le développeur qui s’occupe du bon fonctionnement de la base de données.
En tant que dev front-end, vous serez plus éloigné de la gestion de la DB. En revanche, il vous faudra quand même bien comprendre le fonctionnement général de tout ça, car vous aurez la charge d'afficher correctement ces données, ou bien de discuter avec le dev back pour lui faire des propositions, ou lui demander des informations sur la structure de la base.
Il faudra donc, dans tous les cas, bien comprendre le fonctionnement d'une base de données.
Autres méthodes de stockage de l'information
Il existe d'autres possibilités que les SGBDR pour stocker de l'information, qui peuvent s'avérer plus ou moins adaptées selon les besoins de l'application :
- les bases de données noSQL type Cassandra. Très performantes, mais changement total de conception par rapport aux BDD relationnelles classiques
- les fichiers : peu performant et informations non structurées par un logiciel. Facilité de mise en place. Adapté dans certains cas précis. Cela reste une exception aujourd'hui
- les bases de données clés valeurs : utiles pour stocker des informations simples, rapide, faciles à prendre en main, mais impossibilité faire du relationnel
-
Les GUI (pour Graphical User Interface), au contraire des CLI (Command Line Interface), permettent de travailler sur une base de données via une interface graphique. Vous pouvez très bien vous connecter à votre base de données via un terminal, puis saisir des commandes pour accéder ou modifier vos données. Mais cela est assez fastidieux, et les développeurs utilisent maintenant majoritairement des logiciels de type GUI pour interagir avec leur DB.
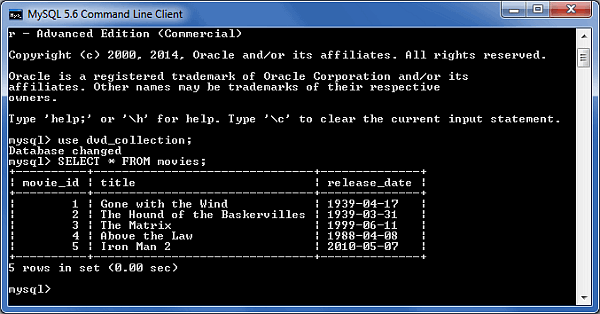
Chaque SGBDR dispose de GUI personnalisés (type phpMyAdmin pour MySQL), mais vous pouvez aussi trouver des solutions "génériques" du type Adminer. Voici un exemple d'utilisation de MySQL via la ligne de commande, et via phpMyAdmin :
MySQL : différence entre CLI et GUI CLI
GUI
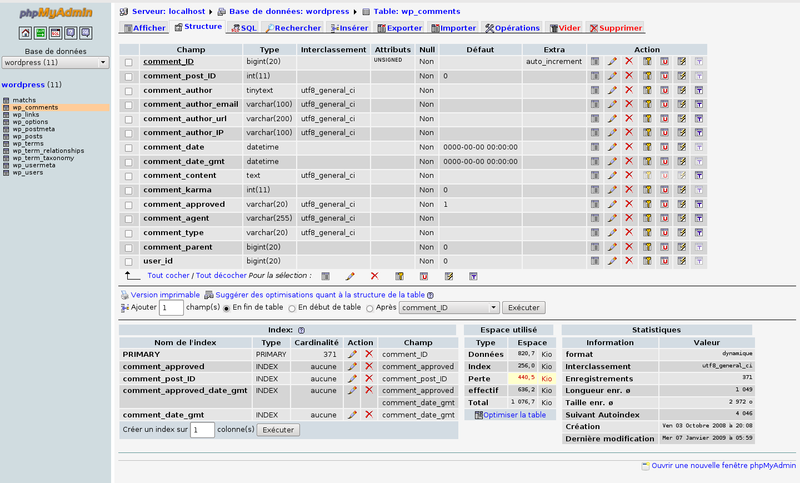
Il y a la deux versions du monde qui s'affrontent. Les puristes vous diront qu'il vaut mieux utiliser la ligne de commande, et ils n'ont pas entièrement tord. Dans certains cas, aucun GUI n'est installé sur le serveur, et il faut donc "attaquer" la DB en ligne de commande. C'est de plus en plus rare, mais cela peut arriver. Donc un bon dev se doit de pouvoir gérer une DB en ligne de commande. En revanche, l'utilisation de GUI est totalement répandue ,et on peux faire exactement la même chose qu'avec une CLI, mais de manière beaucoup plus rapide et facile. Donc pourquoi s'en priver ?
Il existe de nombreuses solutions GUI pour travailler avec une base de données, voici un lien qui illustre différents GUI adaptés à une base de données MySQL : https://codingsight.com/10-best-mysql-gui-tools/
Dans ce cours, nous utiliserons l'éternel phpMyAdmin, mais sachez que vous pouvez théoriquement en utiliser d'autres. Ils font tous à peu près le même boulot, mais ils vont avoir des différences dans :- les performances
- la sécurité
- les fonctionnalités avancées (config, gestion de droits, import/export, etc...)
Voici une liste de différents outils concernant l'administration d'une BDD : https://sql.sh/logiciels
-
Le SQL, pour Structured Query Language, est LE langage qui permet de communiquer avec une base de données. Il est hégémonique sur toutes les bases standards, et au même titre que HTML/CSS pour le front, le SQL est devenu une norme. Et c'est une bonne chose car vous n'aurez pas besoin de connaître autre chose que le SQL pour travailler sur toutes les bases de données habituelles.

Le SQL n'est pas un langage de programmation, ce sont des chaînes de caractères que l'on va envoyer au SGBDR dans le but que celui-ci les interprète, et nous renvoi des données, ou fasse une action particulière dans la base de données.
Voici un exemple basique de requête SQL :
SELECT * FROM users WHERE id = 24;
Cette requête simple est censée renvoyer toutes les informations stockées dans ma BDD qui concerne l'utilisateur ayant l'id 24. Simple non ? On pourra donc récupérer le résultat de cette requête dans une variable de notre programme, puis ensuite la traiter, l'afficher, en faire ce que l'on veux.
Voici un exemple en PHP d'affichage de données provenant d'une DB :
$user = $db->query("SELECT * FROM users WHERE id = $userId");
echo "Bonjour {$user->prenom} {$user->nom} !";Ce code affichera quelque chose comme ceci :
Bonjour Pierre Durand !
Donc pour résumé, le SQL est l'interface entre notre logique (les lignes de code) et nos informations (la base de données).
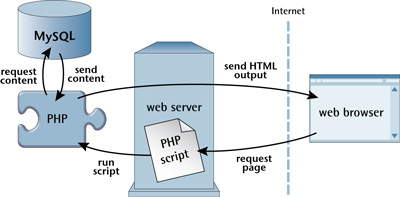
Nuances selon les SGBDR
Malgré le fait que le SQL soit un langage standardisé, il peux exister des différences de syntaxes selon les différents SGBDR du marché. Elles ne sont pas énormes, a vous de vérifier dans la documentation la bonne syntaxe à utiliser selon le SGBDR avec lequel vous travaillez. Mais comme d'habitude, vous trouverez toutes les informations dont vous avez besoin sur le Net. Voici un site qui référence de très nombreuses explications sur le SQL standard : https://sql.sh/
-
Avant de commencer à explorer les bases de données, vérifier bien que vous avez un serveur web local installé, un SGBDR, et une GUI. La stack habituelle est MySQL et phpMyAdmin. Cela se fait assez facilement avec des logiciels types :
- Wamp
- Xamp
- EasyPHP
- etc... (il existe plein d'autres)
Habituellement, les identifiants par défaut sur phpMyAdmin sont :
- user : root
- password : vide (rien)
Ces identifiants sont évidemment à proscrire pour une utilisation en production. Les hébergeurs mutualisés vous créerons un utilisateur dédié avec un mot de passe fort, mais si vous administrez vous même votre serveur, il faudra alors s'occuper de la partie système et gestions de droits utilisateurs pour que l'utilisateur qui se connecte à la DB ai les bons droits. Mais c'est une autre histoire, et cela demande un usage un peu plus avancé.
Etant donné qu'il existe plusieurs manières de faire, je vous laisse fouiller sur Internet pour installer correctement tout ça.
Voici quelques liens utiles :
-
-
Les tables sont l'entité de base lorsque l'on parle de base de données. Une table, c'est une partie d'une DB qui va contenir des informations structurées sur un seul aspect de l’ensemble de vos données. Par exemple, si nous souhaitons réaliser un site d'agence immobilière, la base de données contiendra certainement ce genre de tables :
- annonce (prix, surface, description, ville, etc...)
- villes (liste des villes dans lequel peuvent se trouver les différents bien)
- contact (nom, prénom, numéro de téléphone, etc...)
- photos (liste des photos rattachées à chaque annonce)
- etc...
Ceci n'est qu'un exemple pour vous expliquer le rôle des tables.
Une table se divise en deux parties :
- les colonnes. Elles permettent de structurer l'information, un peu comme un tableaur Excel
- les lignes. Elles permettent de stocker les différentes infos.
Par exemple sur notre table "annonce", on pourrai avoir les colonnes prix, surface, emplacement géographique, etc.. Et chaque ligne correspondrai à un bien immobilier :
- 500€, 45m2, Toulouse
- 450€, 35m2, Blagnac
- 620€, 61m2, Labège
- etc etc...
Il y aura donc autant de lignes qui il y a de bien à proposer dans notre site.
Pour résumé, les tables sont très proches de ce que l'on peux faire avec un tableur Excel, et que vous avez tous déjà certainement fait. Pour gérer un budget par exemple, ou organiser quelque chose.
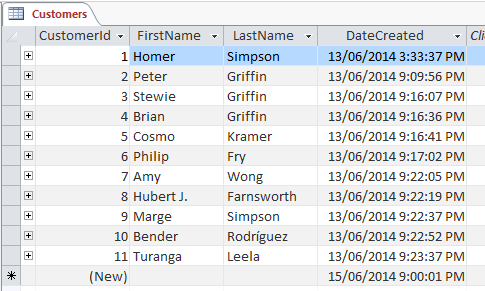
Voici un exemple de table simple :
Et voici un autre exemple, qui ressemble à une base de données permettant la gestion de stock d'un parc informatique :
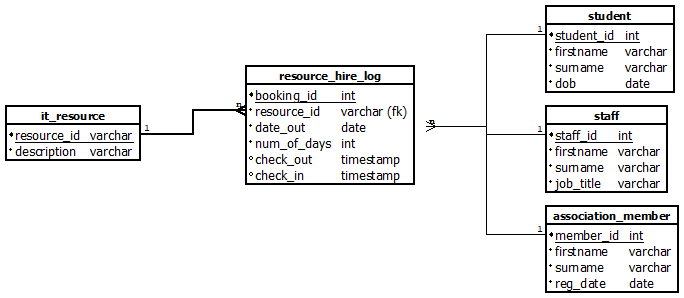
On peux voir dans ce cas que chaque "entité" nécessaire au bon fonctionnement de notre application est présente dans la base de données :
- ressources (le matériel)
- personnes (étudiant, personnel, membre de l'association)
- réservation d'une ressource par une personne
Et chaque entité dispose de données qui lui est propre :
- dob/job title/ reg_date pour les personnes
- informations temporelles pour les réservations
- description pour les ressources
- etc...
-
Une des informations capitales lorsque l'on créé une table, c'est de donner des types au différents champs qui composent notre table. Comme en programmation, on va pouvoir typer tous les champs. Et contrairement à certains langages, ça n'est pas un option. C'est à dire que le SGBDR a besoin de savoir quel type de données vous souhaitez stocker dans l'ensemble de vos champs. Et cela est très utile, car c'est une des première vérification que le SGBDR fera lorsque vous lui demanderez de modifier le contenu de la base.

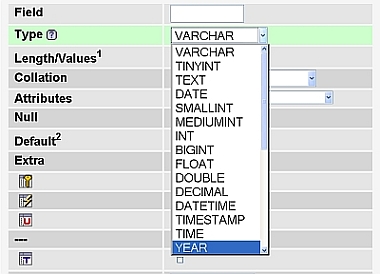
Si vous avez par exemple une colonne "prix", le type sera très certainement "entier". Un prix est forcément un nombre (entier ou a virgules), et vous ne souhaitez pas pouvoir stocker "Bonjour" dans un champ réservé à des prix. Donc il faudra bien penser à typer correctement vos champs lors de la création ou de la modification de votre DB.
Une fois que c'est fait, le SGBDR refusera de stocker tout ce qui ne peut pas être interprété comme un entier dans votre champ "prix".
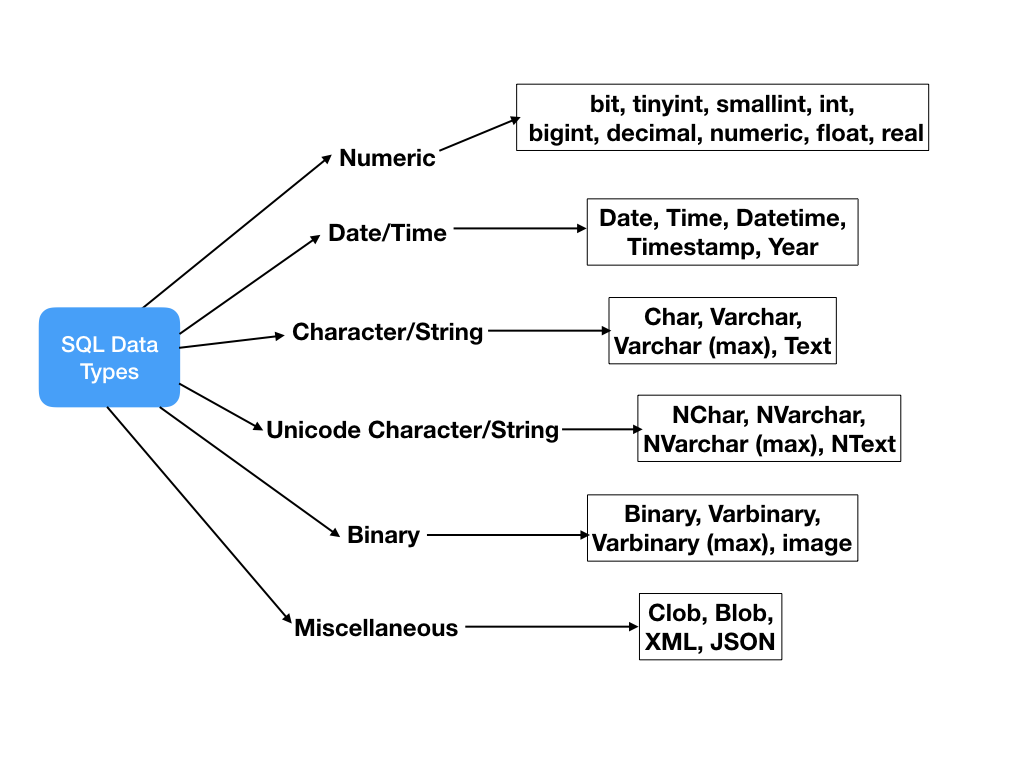
Il y a de très nombreux types de données, et les possibilités peuvent varier d'un SGBDR à l'autre. Il y a des types très répandus (entier, string, dates,...), et d'autres plus spécifique, et moins scalaires (coordonnées GPS, chaîne JSON, mot de passe crypté, etc...).
L'id auto-increment
C'est en général le premier champ que l'on créé automatiquement pour toutes les tables. Il n'est pas obligatoire, mais vous en aurez souvent besoin. L'id auto-increment est un entier que le SGBDR déterminera automatiquement. Pour la première ligne d'une table, l'id vaudra 1, pour la seconde, l'id vaudra 2, etc... C'est ce qui permet d'identifier un élément d'une table via son id, et non par ses "spécificités" humaines (nom d'une personne, nom d'un produit, nom d'une ville, etc...). Quand on parle de base de données, l'id auto-increment est vraiment le point d'entrée de 90% de vos requêtes.
Exemple de création avec phpMyAdmin :

Comme on peux le voir sur l'image, l'auto-increment peux être raccourci en "A.I". Et c'est une option de base de tous vos champs. Si vous cochez cette case, il y a des mécanisme dans la DB qui s'occuperont d'incrémenter automatiquement l'id de chaque nouvelle ligne.
Note : on peux constater ça directement sur le Moodle. Regardez l'URL de ce cours, il a l'id 25. Ce qui correspond à une des entrées d'une des tables constituant le Moodle. Cette façon de procéder est vraiment très répandue.
Les types "nombres"
Il y a différents types de "nombres" lorsque l'on parle typage de données et base de données. On a l'entier simple, qui va être codé sur 4 octets, et vous permettra de stocker des nombres compris entre -2147483648 et 2147483648. Si vous savez que votre entier ne pourra jamais être négatif, vous pouvez choisir l'option "unsigned", ce qui vous permettra de stocker des nombres de 0 à 4294967296.
Il y a aussi des types d'entiers qui vous permettent de spécifier la taille maximale de l'entier :
- bigint pour les très grands nombres
- tinyint pour les petits nombres
- etc...
Ces nuances vous permettent d'avoir une description plus précise de vos données, et surtout d'optimiser le fonctionnement de votre table. Si par exemple vous stocker de petits nombre (23, 45, 7, 85,...) dans un champ prévu pour des grands nombres (bigint), et bien vous allez perdre énormément d'espace disque, car le SGBDR va réserver un nombre d'octets bien supérieur au besoin réel de ce champ.
Vous retrouverez aussi les types permettant de stocker des nombres à virgules :
- float
- double
- decimal
- etc...
Ces types fonctionnent de la même manière que les entiers. La différence tiens au fait que l'information, au sens binaire du terme, contiendra des éléments sur la position de la virgule par exemple.
Au même titre que les autres, vous ne pourrez pas stocker un entier dans un champ float. D'un point de vue dlogiciel, il y a une différence entre :
- 23 (entier)
- 23.00 (nombre à virgule)
Les types texte
Les données de type texte sont très représentées dans les base de données. Elles peuvent servir pour stocker différents types d'information, du "flag" technique qui permet de sauvegarder un état (exemple, type de compte : Secrétaire, Client, Technicien, etc...). Ou bien un gros pavé de texte à l'intérieur du forum, qui contiendra un texte très long.
Voici quelques exemples de type texte :- Char : permet de ne stocker une chaîne avec un nombre défini de caractères (taille fixe dans la DB)
- Varchar(x) : permet de stocker entre 0 et x caractères. Par exemple, un champ dédié aux e-mails pourrait utiliser ça VARCHAR(256). Car un e-mail fait rarement plus de 256 caractères. (taille variable dans la DB)
- Text : pour de long texte (65535 caractère), et toutes ses variantes (tinytext, mediumtext, longtext), comme les entiers.
- etc...
Les dates
Les dates sont très utilisées dans les bases de données. On souhaite très souvent savoir, les dates de création ou de modification des différentes données présentes dans notre système. Il y a de très nombreux exemples ou l'usage du temps est nécessaire (ERP, agendas, blog, etc...). Les bases de données offrent donc des types spécifiques pour stocker ce genre d'informations, en voici quelques uns :
- Date : sert à stocker les dates, sans les heures
- Datetime : sert à stocker une date et une heure
- Timestamp : sert à stocker le temps sous forme de Timestamp Unix (un entier représentant le nombre de seconde depuis le 1 janvier 1970)
- etc...
Autres type
Il existe de nombreux autres types, mais qui sont moins représentatifs de l'usage courant, et qui vont être géré de manière plus spécifique selon les SGBDR.
Par exemple, avec MySQL vous avez un type Boolean qui peux s'avérer être très adapté dans de nombreux cas (tout ce qui peux s'exprime via une valeur booléenne). Sauf qu'en réalité, MySQL considère ça comme un TinyINT qui est borné aux valeurs 0 pour false, et "tout le reste" pour vrai. Ca n'est donc pas un type en soi, mais un usage détourné du TinyINT.
Pour le reste ,allez faire un tour dans phpMyAdmin pour voir les différents types existant. Voici un lien vers la doc officiel des types MySQL : https://dev.mysql.com/doc/refman/8.0/en/data-types.html
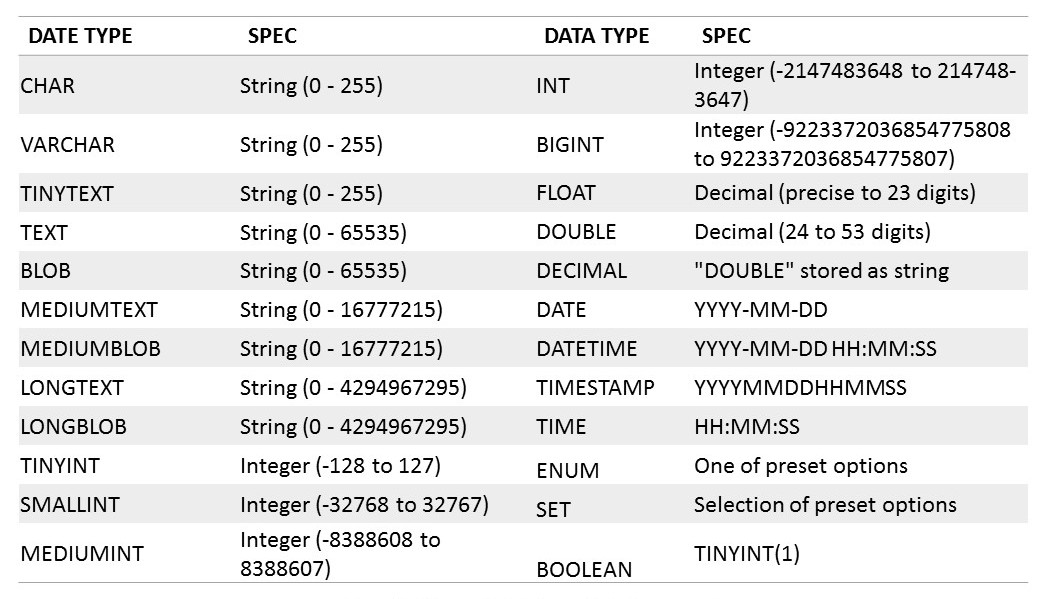
Résumé :
-
Taille du champ
La taille du champ est une donnée importante, car elle va vous permettre de limiter la taille de types qui ont une taille variable (exemple VARCHAR 0 à 256). Par exemple si vous mettez un VARCHAR a 30, tout ce qui dépassera 30 caractères sera "coupé" par le SGBDR. Elle peut aussi servir dans les champs de type ENUM pour signifier la liste de valeurs autorisées, et dans d'autres cas de figure (limiter la taille d'un entier, etc...).
Valeur par défaut
Comme son nom l'indique, cette propriété permet de définir une valeur par défaut à un nouveau champ. Si par exemple vous devez gérer un champ "utilisateur actif", n'ayant que deux valeurs possibles (1 pour actif ou 0 pour inactif), et que vous souhaitez que les comptes utilisateurs soient actifs par défaut, alors vous devrez mettre la valeur "1" dans la propriété "valeur par défaut".
Rendre un champ NULLABLE
Comme dans la plupart des langages de programmation, on retrouve la valeur NULL dans les SGBDR. Cela permet d'avoir une valeur sur un champ qui n'a pas encore été renseigné. Cela évite d'avoir la valeur "chaine vide", ou "zéro", qui peuvent être un peu plus ambiguës.
Aussi, lorsque vous ferez des requêtes SQL sur votre base de données, le fait de chercher une valeur NULL ou bien une valeur "chaîne vide" ou "zéro", ne s'écrira pas de la même manière et pourrait donner des résultats différents.
Voici un exemple sur le champ "budget" de la table "client" :

Dans cet exemple, un budget NULL sera plus précis qu'un budget défini à 0€. Le client peut ne pas encore avoir budgétisé son projet...
Dans certains cas, rendre un champ NULLABLE n'a aucun sens : auto-increment, timestamp automatique, ou encore quand une donnée est obligatoire (exemple : l'email d'un utilisateur).Voici un lien vers la doc MariaDB (EN) pour la valeur NULL : https://mariadb.com/kb/en/null-values/Interclassement
C'est l'encodage du jeu de caractère (UTF-8, Latin-1, etc...) pour un champ en particulier. En théorie, on essaye d'avoir le même jeu d'encodage pour toute une base de données, mais ça peut arriver (sur des vieux projets par exemple, ou sur du multilingue) de devoir jouer sur plusieurs jeux d'encodage au sein de la même base de données. On pourra donc spécifier, champ par champ, le jeu d'encodage désiré. Mais on essaiera toujours de garder l'encodage principal de la DB en priorité.
Attributs
En fonction des SGBDR, ce champ peut proposer différentes options, telles que :
- les entiers signés ou non-signés, ce qui peut être utile sur des données qu'on sait n'être que positives (prix par exemple)
- mettre à jour automatiquement le timestamp courant lors d'une modif d'un champ (CURRENT TIMESTAMP)
- etc...
-
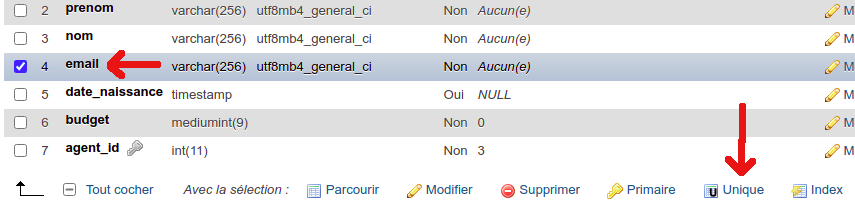
Vous pouvez aussi "forcer" une donnée à être considérée comme unique dans une table (par exemple : un email), sans pour autant être obligé d'en faire une clé primaire. Cela peut s'avérer utile dans certains cas, par exemple lorsque vous souhaitez bénéficier de la couche "vérification des données" que vous offre le SGBDR (un email ne peut exister qu'une seule fois pour un seul utilisateur), sans pour autant vouloir surcharger l'index de votre table, car vous n'aurez que peu de recherche par email.
Voici comment mettre un champ en UNIQUE dans phpMyAdmin (onglet structure) :
Et voici un exemple de "mauvaise manip", si on essaye de mettre deux fois le même email à deux clients différents :
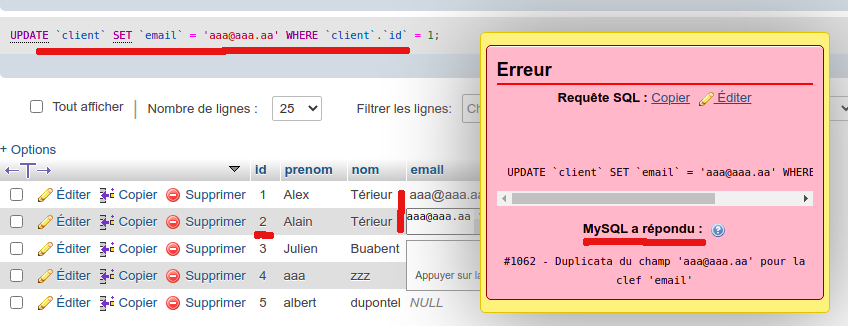 Attention : si vous mettez une contrainte UNIQUE sur une table qui contient déjà des champs remplis, vous pouvez générer des erreurs d'intégrité, car un champ vide (chaîne vide) peut être considéré comme une valeur comme les autres. Vous pouvez aussi avoir deux champs qui ont déjà une valeur identique. Dans ces cas, il vous faudra revoir ou nettoyer le contenu de votre table avant de pouvoir mettre la contrainte UNIQUE sur le champ désiré, afin d'en supprimer tous les doublons en premier lieu. Exemple : donner la valeur NULL aux champs vides, lancer une requête SQL qui remet tout à plat (ou à zéro), etc... Cela dépendra de l'étendue de votre problème (réparation manuelle ou automatisée), et de votre SGBDR.
Attention : si vous mettez une contrainte UNIQUE sur une table qui contient déjà des champs remplis, vous pouvez générer des erreurs d'intégrité, car un champ vide (chaîne vide) peut être considéré comme une valeur comme les autres. Vous pouvez aussi avoir deux champs qui ont déjà une valeur identique. Dans ces cas, il vous faudra revoir ou nettoyer le contenu de votre table avant de pouvoir mettre la contrainte UNIQUE sur le champ désiré, afin d'en supprimer tous les doublons en premier lieu. Exemple : donner la valeur NULL aux champs vides, lancer une requête SQL qui remet tout à plat (ou à zéro), etc... Cela dépendra de l'étendue de votre problème (réparation manuelle ou automatisée), et de votre SGBDR. -

Identification
Comme vous avez dû le voir dans l'exercice précédent, le champ "id" est considéré comme clé primaire par défaut. Cela veux dire pour le SGBDR que deux lignes ne peuvent pas avoir le même id. Ce qui est ultra important, si deux champs ont le même id, lequel choisir lorsque vous souhaitez récupérer les informations de l'annonce n°124 ? Donc en déterminant un champ comme clé primaire, le SGBDR va mettre en œuvre un mécanisme de vérification qui vous interdira d'avoir deux fois le même identifiant.

Une clé primaire peux se mettre sur n'importe quel champ, le SGBDR l'acceptera. En revanche, il serait illogique de mettre une clé primaire sur la surface par exemple, car deux appartements peuvent très bien avoir la même surface (ex: 75m2).
Pour résumé, un champ qui est une clé primaire est à la fois UNIQUE et indexé. Ce champ servira de "porte d'entrée" principale à toutes les requêtes concernant sa table.Couple de clés primaires
On peut aussi déterminer plusieurs champs comme une clé primaire. On pourrait, par exemple, décider de choisir le nom et le prénom d'une personne pour l'identifier dans la base de données. Ce qui nous ferait donc deux clés primaires (nom/prénom), et c'est totalement possible. Le SGBDR vérifiera alors que le couple nom/prénom n'est pas déjà présent dans la table avant d'insérer nos données.
Cette approche empêcherai de faire des homonymes, ce qui reflète mal la réalité. Deux personnes peuvent porter le même nom/prénom, c'est pour cela que l'on identifie le plus souvent les enregistrements via un id numérique et unique. Mais dans certains cas, ce sera très utile d'avoir un couple de champs en clé primaire.
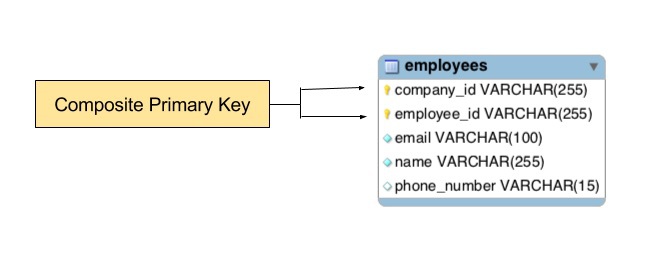 Note : on peut mettre plus que 2 clés primaires. Il n'y a pas vraiment de limite, si ça n'est la cohérence de la conception.
Note : on peut mettre plus que 2 clés primaires. Il n'y a pas vraiment de limite, si ça n'est la cohérence de la conception. -
Une base de données ne comporte généralement pas qu'une seule table. On va donc avoir besoin de créer plusieurs tables qui reflètent chacune une entité nécessaire au bon fonctionnement de notre application. En revanche, ces tables sont bien souvent reliées entre elles pour des besoins d'intégrité de l'information. Pour prendre exemple sur notre site d'agence immobilière, une annonce sera bien rattachée à une ville. Logique.
On sera rendre compte vite compte que toutes les données sont liées les unes aux autres :
- un appartement est rattaché à une ville, mais a aussi un type (maison, loft, etc...)
- un client est géré par un commercial (mais un commercial peut gérer plusieurs clients)
- etc...
On a donc des entités distinctes (villes, annonces, etc...), mais reliées entre elles pour les besoins de modélisation conceptuel des données. Le SGBDR se chargera de vérifier l'intégrité de ce qu'on lui demande de faire avant de le faire réellement.Pour relier deux tables entre elles, les SGBDR offre une fonctionnalité de base qui se nomme "clé étrangère" (foreign key en anglais). C'est une contrainte que l'on va donner à un champ, et qui va obliger le SGBDR à vérifier que cette contrainte est bien respecté, afin de garantir l'intégrité des données.
Dans notre exemple d'agence immobilière, on va pouvoir relier une annonce a une ville. Chaque bien étant localisé dans une ville, cela semble logique. Et bien au lieu de laisser un champ de saisie libre (par exemple : ville) dans la table annonce afin de laisser l'utilisateur saisir librement la ville son choix, on va rajouter un champ de type ville_id, et on va contraindre ce champ à n’accepter que les id des villes présent dans la table ville. Et ceci via la mise en place d'une clé étrangère ville_id de la table annonce.
On peut donc écrire ceci, en français : le champ ville_id de la table annonce est relié au champ id de la table ville.
Et voici une syntaxe un peu plus proche du SQL : annonce.ville_id => ville.id
Définir une clé étrangère dans phpMyAdmin avec MariaDB
Important : cet exemple a été réalisé avec MariaDB. Pour faire la même chose avec MySQL, il vous faudra créer un index sur votre champ ville_id avant de créer la clé étrangère. Pour vérifier quel SGBDR est installé sur votre ordinateur, allez dans la page d'accueil de phpMyAdmin :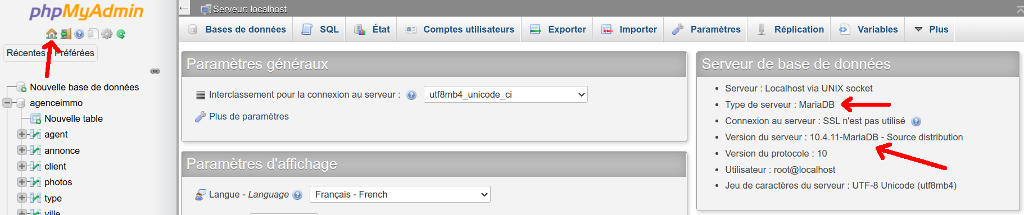
Voici la marche à suivre pour mettre en place une clé étrangère :
1 - créer le nouveau champ ville_id dans votre table annonce. Il doit être du même type que votre clé étrangère (donc un futur id). N'oubliez pas de mettre une valeur par défaut à un si vous avez créé des villes.
2 - dans votre table annonce, ouvrez la vue relationnelle dans l'onglet structure
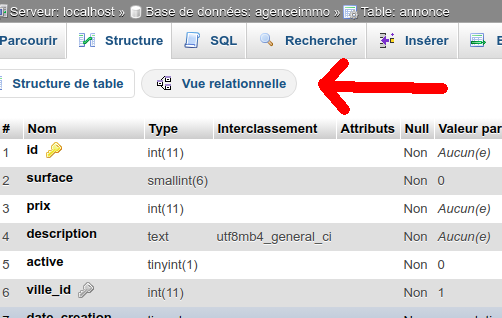
3 - définissez votre nouvelle contrainte de clé étrangère. Il vous faudra dire quel champ de votre table (colonnes) doit être relié à quel autre champ dans la BDD (contrainte)

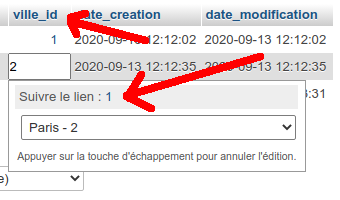
4 - vous pouvez maintenant associer chaque annonce aux villes présentes dans la table ville :
5 - et constatez le résultat dans l'outil concepteur de phpMyAdmin. Le lien vert représentant la contrainte de clé étrangère entre annonce est ville.
 Note : on aurait aussi pu le faire directement en SQL de type ALTER TABLE. On reverra ça dans le cours sur SQL.
Note : on aurait aussi pu le faire directement en SQL de type ALTER TABLE. On reverra ça dans le cours sur SQL.Autres exemple de clés étrangères Chaque employé est rattaché à un département : 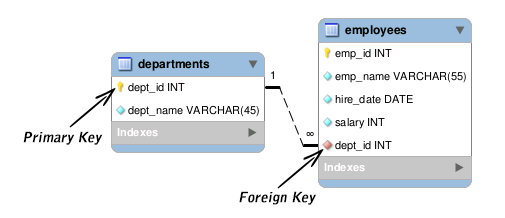
Chaque enregistrement est rattaché à un artiste et à un style musical : 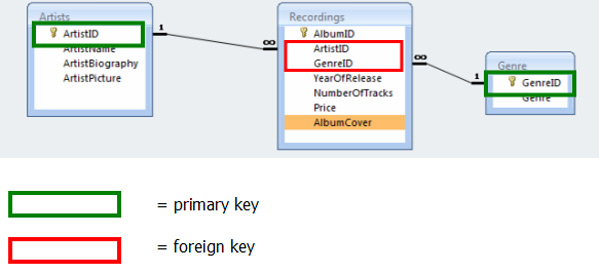 Bref, vous allez devoir déterminer des relations entre les tables afin que le SGBDR puisse jouer son rôle de vérification de l'intégrité des données.
Bref, vous allez devoir déterminer des relations entre les tables afin que le SGBDR puisse jouer son rôle de vérification de l'intégrité des données.